
티스토리 뷰
- 컨텐츠 기반 필터링
- 협업 필터링
- 하이브리드 필터링
협업 필터링 vs 컨텐츠 필터링
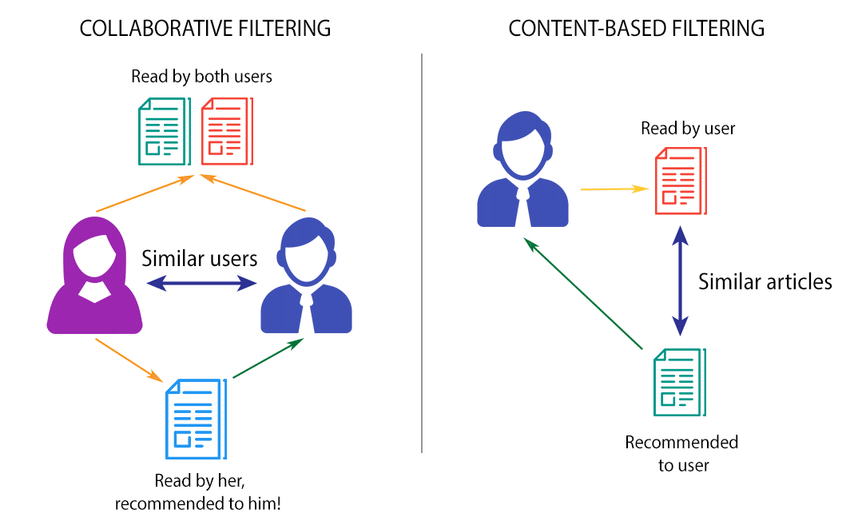
"너가 좋아했던 그거, 그거 찾던 애들은 이것도 찾던데? " vs "너 그거 좋아했으니, 그거랑 비슷한 이것도 좋아할 거야!"
컨텐츠 기반 필터링(Contents - Based Filtering)
"너 그거 좋아했으니, 그거랑 비슷한 이것 도 좋아할 거야!"
컨텐츠 필터링 구현 절차
1) 피처 추출
- 아이템의 유사성을 계산하기 위해, 아이템의 특성을 추출
- 상품의 특징을 담은 tabular feature 사용하거나, 텍스트의 경우 TF-IDF 기법 적용
2) 사용자 프로필 정보 생성
- 유저의 선호도를 나타내는 역할 수행
- 유저가 상호작용한 아이템의 특징을 집계하여 생성
3) 유사도 계산
- 아이템과 사용자 프로필 벡터 사이의 유사도를 계산
- 코사인 유사도, 유클리드 거리, 피어슨 상관계수 등을 활용
4) 랭킹
- 유사도 스코어에 다라 순위를 매기며, 상위의 아이템을 사용자에게 추천
컨텐츠를 피처로 표현하는 방법
1) 수치 형태로 표현하기
- 각 아이템의 특성을 feature로 표현
- 연속형 변수 : 정규화 후 수치 형태로 사용
- 범주형 변수 : one-hot encoding등의 가공 방식 사용
2) BoW (Bag of Words) 방식
- 단어마다 feature로! 문장을 벡터로 만드는 방식, 문장 내 Words를 토큰으로 만들어 Bag 안에 넣자!
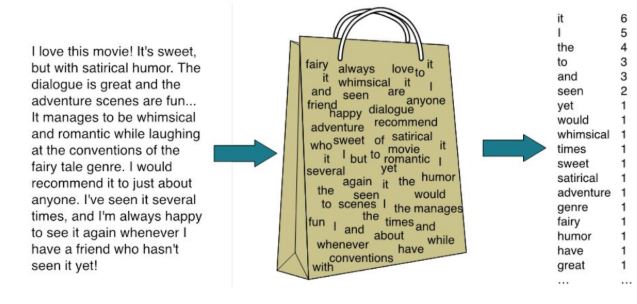

- 문장 내 단어가 늘어감에 따라 feature의 수 지나치게 크게 증가
- 연산 효율 문제 발생
- 단어간의 의미 관계 포착 불가! 단순히 독립된 벡터 공간 내에서 하나의 feature로 간주하므로!
- 불용어(stop words) 문제
3) TF - IDF (Term Frequency - Inverse Document Frequency) 방식
- 자주 나오는 단어 중요하나, 어디서나 자주 등장하는 단어는 제외한다!
- 문장 내 단어는 문서별로 다른 중요도를 가진다!
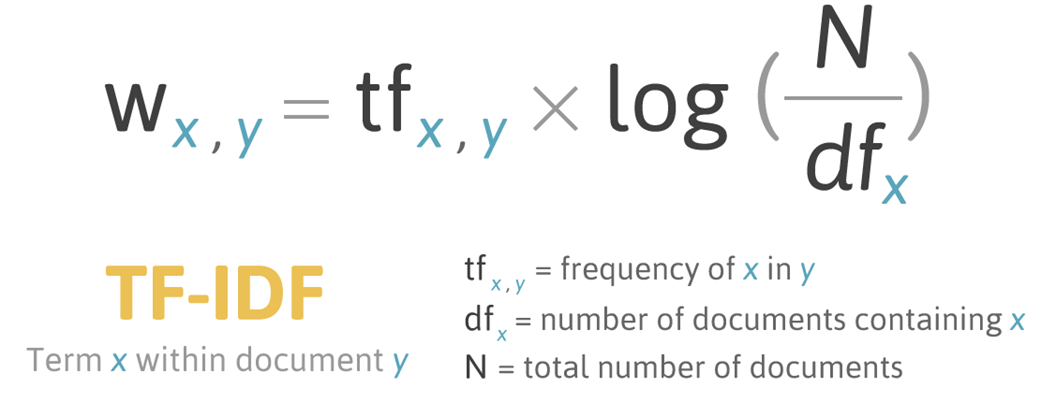
- TF(Term Frequency) : 문서 y 내 x라는 단어의 등장 빈도, 문장 내 자주 등장하는 단어는 더 중요하다
- IDF(Inverse Document Frequency) : 전체 문서의 수 / x라는 문장을 포함하고 있는 문서의 수 → 많이 등장하면 패널티!
많이 등장하는 여러 문장에 걸쳐 자주 등장하는 단어는 별로 안 중요함! like 불용어(stopwords)..
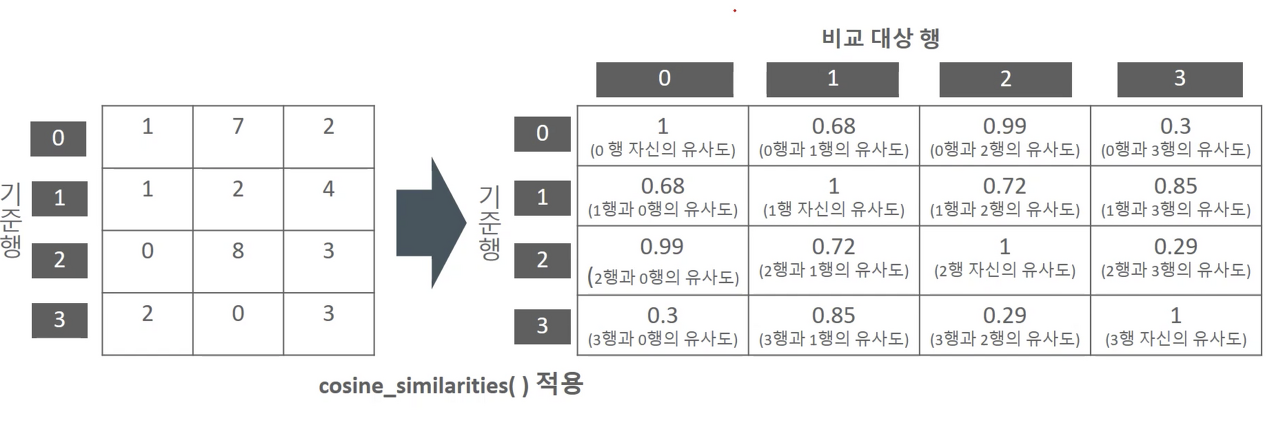
유사도 계산
- 유사도를 계산하는 방식에는 다양한 방법들이 존재
(1) 코사인 유사도 ( Cosine Similarity) ⭐
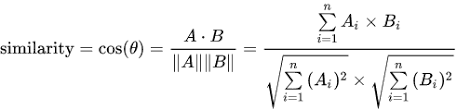
(2) 유클리드 거리 (Euclidean Distance)
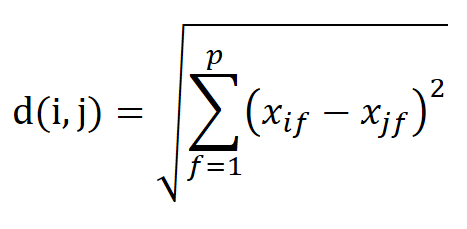
(3) 피어슨 상관계수 (Pearson Correlation Coefficient)
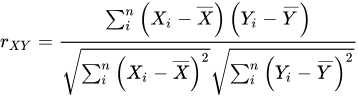
콘텐츠 필터링의 장단점
[장점]
- 적은 상호작용 데이터에도 사용가능, cold - start 상황에 적합
- 아이템 cold start에 강점 : 상호작용이 전혀 없어도 추천 가능
- 추천 해석 가능 : 어떤 피처가 추천에 도움이 되었는지 근거를 찾을 수 있음
[단점]
- 아이템 피처의 한계 : 피처 정보로만 유사도를 계산하므로, 피처 품질에 영향 받음
- 신규 유저 cold start : 아무런 아이템도 클릭한 적 없는 유저에겐 추천 어려움
협업 필터링 (Collaborative - Based Filtering)
"너가 좋아했던 그거, 그거 찾던 애들 은 이것도 찾던데?"
협업 필터링 종류
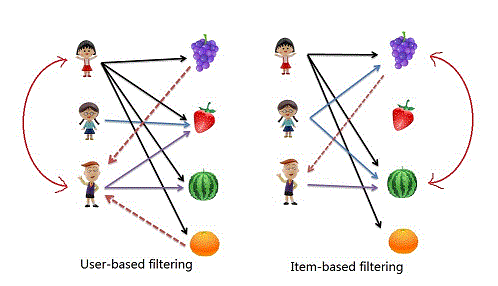
- User - Based Collaborative Filtering : 유사한 취향을 가진 이웃을 사용자 관점에서 찾는다
- Item - Based Collaborative Filtering : 유사한 취향을 가진 이웃을 상품 관점에서 찾는다
협업 필터링 구현 절차
1) 유저 - 아이템 상호작용 행렬 생성
- 유저를 행에, 아이템을 열에 두어 행렬을 생성
- 각 유저- 아이템이 평가/클릭/구매 등 상호작용한 정보를 기반으로 원소 채움
2) 유사도 계산
- 유저 기반 협업 필터링의 경우 평가한 아이템의 index를 feature로 간주
- 아이템 기반 협업 필터링의 경우, 각 아이템을 평가한 유저들의 index를 feature로 간주
- 각 유저별/ 아이템별 유사도 계산
3) 이웃 지정
- 추천 대상의 스코어를 생성할 이웃 유저/아이템을 지정
- 높은 유사도의 유저 n명을 사용
4) 랭킹
- 이웃들의 상호작용 정보를 토대로 추천 스코어 계산
💡 유사도를 계산하는 방법은 앞선 컨텐츠 필터링과 마찬가지로 코사인 유사도와 같은 방식 활용!
💡 유사도 계산시, 사용자 특성으로 계산하는게 아니라 item 선호도를 기반으로 계산됨!
콘텐츠 필터링의 장단점
[장점]
- 사용자의 과거 행동을 기반으로 유사한 집단을 찾아 개인화된 추천 재공
- 잠재적 특징 활용 : item/ user feature로 명시적으로 드러나지 않은 선호정보도 반응정보로 부터 추출하여 사용하므로 폭 넓은 추천 가능
- interaction 데이터가 쌓일수록 더 정교하고 풍성한 추천 가능
[단점]
- 아이템 cold start : 한번도 추천되지 않은 아이템은 추천될 수 없음
- 유저 cold start : 과거 상호작용 데이터에 의존
- 낮은 확장 가능성 : 아이템/유저 수가 늘어남에 따라 연산량 급격히 증가
하이브리드 필터링
협업필터링 + 컨텐츠 기반 필터링
- Combining Separate Recommenders
- 단순하게 여러 모델의 결과값을 평균 내어 사용 or 성능을 기준으로 더 좋은 성능에 가중치
- 더 좋은 모델 선택하기 - Feature Combination
- 앞선 모델의 추천 결과(주로 협업 필터링)를, 이후 등장하는 메인 모델의 피처로 사용
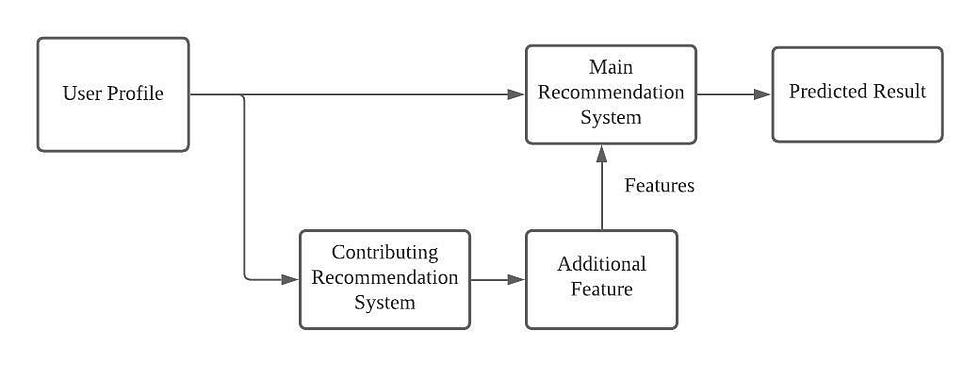
- 협업 필터링 추천 결과를 고려해 콘텐츠 필터링을 적용함으로써 두 모델의 장점 적절히 조합 가능
- ex) 협업 필터링으로 알아낸 user들의 공포 영화 선호도를 feature로 사용해서 contents 필터링 진행
- Switching
- 그때 그때 적절한 모델 사용!
- cold user 상대로는 item 기반 추천, 활동 기록이 쌓이면 협업 필터링 적용
하이브리드 필터링 장단점
[장점]
- 성능 향상, 두 모델을 조합함으로써 각 모델의 강점 활용, 약점 상쇄
- 전반적인 추천 성능의 증대 가능
- 추천 범위, 다양성의 증가, cold start 문제 개선
→ 피처 기반 추천함으로써 cold item 추천 가능 / 협업 기반 추천함으로써 다양한 상품 추천 가능
[단점]
- 복잡도의 증가, 확장성 감소
- 하이퍼 파라미터, 모델 가중치 등 추가적인 튜닝 필요
[ 참고 문헌 ]
'RecSys' 카테고리의 다른 글
| [RecSys] Sequential Recommendation (0) | 2023.09.24 |
|---|---|
| [RecSys] 3. Matrix Factorization (0) | 2023.09.17 |
| [RecSys] 1. 추천시스템 개념 및 고전 추천 알고리즘 (0) | 2023.08.29 |
| [RecSys] SASRec Position Embedding Experiments (0) | 2023.07.12 |
| [RecSys] SASRec 코드 리뷰 (0) | 2023.07.12 |
- Total
- Today
- Yesterday
- SQL레시피
- 하이브리드 필터링
- 여러개 값에 대한 조작
- WHERE문 집계함수
- treer구조
- 고전적 추천 알고리즘
- 연관규칙분석
- NULL인 열 만들어주기
- groupby 다중
- 숨겨진조건
- SET문
- 이코테
- pointwise reranker
- llm reranker
- 알고리즘
- 추천시스템
- cold-start
- Lagrange Multipler
- 서브쿼리
- SQL
- NULL AS
- ORDER BY LIMIT
- 다중 GROUP BY
- reranker 속도 개선
- 하나의 테이블에 대한 조작
- SELECT문 안 서브쿼리
- WHERE절서브쿼리
- SASRec
- rag 다중문서 활용
- reranker
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |