
티스토리 뷰
Intro
Collaborative Filtering 은 크게 봤을 때 neighborhood method와 latent factor models 2가지로 나눌 수 있음
neighborhood method는 user들 끼리 or item 끼리 유사도를 측정해서 유사한 선호도를 가지는 item의 추천을 진행하는 방식이었다면, latent factor model은 관찰된 데이터 속에서 잠재되어 있는 유저와 아이템의 특성을 뽑아내서 유사한 정도를 파악하고 추천을 진행하는 방식이라고 볼 수 있음!
Matrix Factorization 행렬 분해
Interaction Matrix ( 상호작용 행렬 )
각 유저가 아이템에 대해 매긴 평점, 혹은 구매/클릭 여부를 나타낸 행렬
→ 유저의 직접적/간접적인 선호가 드러나 있음!
- (User 의 수) * (Item의 수) 로 구성되어 있으며, 구매 여부처럼 Implicit 한 Feedback 이 들어갈 수도 , 평점과 같은 Explicit 한 Feedback이 들어갈 수도 있다
- 일반적으로 결측값이 많기에 Sparse 한 Matrix가 된다!
Matrix Factorization (행렬 분해)
- 상호작용 행렬을 두개의 작은 행렬로 쪼개어, 그들의 곱으로 유저의 평점을 예측하는 모델
- 각각 행렬은 유저 잠재 요인, 아이템 잠재 요인을 나타냄

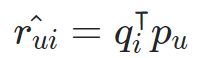
- User - Item Matrix가 User와 Item latent factor 행렬곱으로 분해!
- M명의 사용자 x N개의 item으로 구성되어 있던 M x N 행렬이 M x K ( 사용자 행렬 ) 과 N x K (아이템 행렬)로 분해
이때, K는 latent vector의 개수
- '분해' 되는 과정에서 Noise 는 제거되고 데이터 사이 중요한 패턴은 압축된다! → 효율성 증대!
Latent Vector란?
latent vector란, 복잡한 특성을 시공간내로 맵핑할 수 있도록 만들어주는 큰 축이라고 설명할 수 있다!
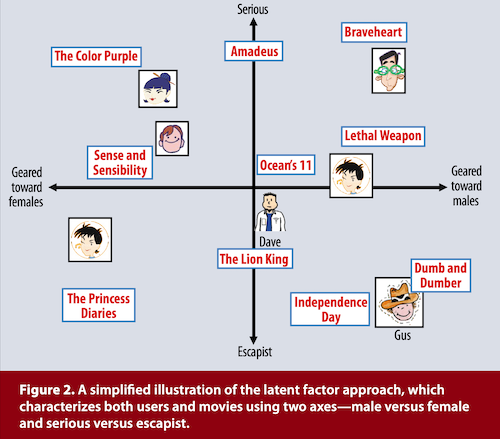
- 위와 같은 그림에서, 다양한 특성을 지닌 영화들을 y축은 현실적인지 / 비현실적인지 여부로, x축은 남성/ 여성 선호 인지 두가지 축을 기준으로 분류한 것을 볼 수 있음!
- 이와 같이, 복잡한 특성들을 큰 축으로 맵핑해주는 것이 Matrix Factorization이라고 할 수 있으며, 위 사진 속 latent vector는 현실적인지 여부, 성별별 선호 처럼 사람이 해석가능하지만, 실제로는 사람이 해석할 수 없는 수치값으로 표현된다! (일종의 embedding 개념이라고 이해해도 될 듯!)
- 이때, 이러한 latent factor를 어떻게 찾아내느냐가 Matrix Factorization 알고리즘의 핵심 요소!
cf) SVD
- SVD 또한 원래의 행렬을 3개의 행렬로 분해하고, 원래의 행렬로 재현하는 개념이기에 유사한 개념이라고 볼 수 있음
- 그러나, user - item 행렬에는 sparseness성 때문에 많은 결측값들이 존재할 수 밖에 없으며, SVD는 Sparse Matrix에 적용이 어렵!
→ MF에서는 결측값들은 제외하고 관측된 선호도만을 사용해줌! P, Q 학습 시킨후, 원래 결측값들을 다시 예측해주는 방식으로 진행
MF 학습
- 참고로, MF에서 train / test split은 holdout 방식이 아님! 행렬 형태로 구성되어 있기에 일부 유저만 사용할 경우 행렬 형태가 망가진다!
- 따라서, 행렬의 일부를 마스킹 하는 형태로 train / test split을 진행해준다!
학습은 다음과 같은 방식으로 진행된다.
1. 잠재요인 K개 선택
2. 사용자 행렬 P, 아이템 행렬 Q 행렬 초기화
3. 예측 평점 r hat 계산
4. 실제 R과 r hat 간 오차 계산 및 X, Y 수정
5. 기준 오차 도달 확인
loss function
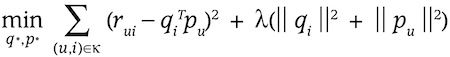
- p : user latent vector
- q : item latent vector
- p와 q를 곱하여 얻은 예측 평점 행렬의 오차가 최대한 작아지도록 수식을 구성함!
- 앞부분은 예측된 행렬과 실제 행렬간의 차이를 의미하고, 뒷부분은 오버피팅을 막기 위한 Regularization 부분!
Optimization
최적화 기법은 대표적으로 2가지를 활용!
SGD ( Stochastic Gradient Descent)
- 많은 딥러닝 기법들에서 사용하는 SGD!

- 실제 선호도와 예측된 선호도의 차이를 예측오차로 정의
- 예측 오차를 p와 q로 편미분 시켜 현재 위치의 gradient 반대방향으로 p와 q를 업데이트 시켜준다.
ALS ( Alternating Least Squares)
- 최적화 시, 두 행렬 중 하나의 행렬은 Freeze(고정)하고, 다른 한 행렬만을 최적화한다!
- 병렬화 (Parallelization)가 가능할 때, 다른 item의 qi와 다른 user의 pu를 병렬적으로 계산할 수 있기에 빠른 연산이 가능
- Implicit feedback 처리에 유용함!
- Explicit feedback에 비해 implicit feedback은 dense함! 평점과 같은 explicit data는 일반적으로 비어있는 sparse한 경우가 많았다면, 클릭 여부와 같은 implicit data는 보통 클릭한 것보다 클릭하지 않은 것들이 더 많으므로 dense함
- dense하므로 연산량이 많을 수 밖에 없음! → 병렬 처리가 유리하다
[ 참고 문헌 ]
- 패스트 캠퍼스 강의 : 30개 프로젝트로 끝내는 추천시스템 구현 초격차 패키지 | 패스트캠퍼스 (fastcampus.co.kr)
- MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS 논문 : Recommender-Systems-[Netflix].pdf (datajobs.com)
'RecSys' 카테고리의 다른 글
| [RecSys] Sequential Recommendation (0) | 2023.09.24 |
|---|---|
| [RecSys] 2. 컨텐츠 기반 필터링과 협업 필터링 (1) | 2023.08.29 |
| [RecSys] 1. 추천시스템 개념 및 고전 추천 알고리즘 (0) | 2023.08.29 |
| [RecSys] SASRec Position Embedding Experiments (0) | 2023.07.12 |
| [RecSys] SASRec 코드 리뷰 (0) | 2023.07.12 |
- Total
- Today
- Yesterday
- rag 다중문서 활용
- treer구조
- reranker 속도 개선
- pointwise reranker
- 알고리즘
- groupby 다중
- 숨겨진조건
- 여러개 값에 대한 조작
- 다중 GROUP BY
- SQL
- SQL레시피
- 추천시스템
- 서브쿼리
- SASRec
- NULL인 열 만들어주기
- 하이브리드 필터링
- 연관규칙분석
- 고전적 추천 알고리즘
- WHERE문 집계함수
- cold-start
- 하나의 테이블에 대한 조작
- SET문
- ORDER BY LIMIT
- 이코테
- WHERE절서브쿼리
- NULL AS
- SELECT문 안 서브쿼리
- llm reranker
- reranker
- Lagrange Multipler
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |