
티스토리 뷰
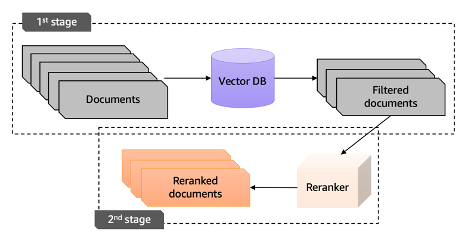
Reranking 정의
RAG가 생성한 후보 문서들에 대해 질문에 대한 관련성 및 일관성을 판단하여 문서의 우선 순위를 재정렬하는 것즉, 질문과 관련성 있는 문서들을 컨텍스트의 상위권에 위치시킴으로써, 답변의 정확도를 올리는 방법
진행 방향
w/o or w/ Filtered documents
LLM 활용 방법론(Utilizing LLMs as Unsupervised Rerankers)

(1) Point-wise methods
- (query,document) 쌍을 제공해서 LLM한테 (query, document) 가 얼마나 relevant한지 점수를 매기는 방법
a. relevance generation - 해당 쿼리와 문서가 관련이 있을 확률을 LLM이 generation 하도록 하는 방법

- Holistic Evaluation of Language Models, Liang et al., arXiv 2022. [Paper]
- Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels, Zhuang et al., arXiv 2023. [Paper] : (Not Relevant”, “Somewhat Relevant”, “Highly Relevant”) 처럼 3개로 나눠서 답하게 물어보는 것이 zero-shot 셋팅에서 랭킹에 더 효율적이라는 내용
b. query generation
Improving Passage Retrieval with Zero-Shot Question Generation, Sachan et al., EMNLP 2022. [Paper] -> UPR ReRanker

UPR Reranker ?
LLM에게 passage만을 주고, passage에서 만들 수 있는 질문 생성 -> LLM이 생성한 질문과 user의 질문이 얼마나 비슷한지 점수를 매기고, 그 점수로 rerank하는 방법
- Open-source Large Language Models are Strong Zero-shot Query Likelihood Models for Document Ranking, Zhuang et al., EMNLP 2023 (Findings). [Paper]
- Discrete Prompt Optimization via Constrained Generation for Zero-shot Re-ranker, Cho et al., ACL 2023 (Findings). [Paper]
- PaRaDe: Passage Ranking using Demonstrations with Large Language Models, Drozdov et al., EMNLP 2023 (Findings). [Paper]
- InstUPR: Instruction-based Unsupervised Passage Reranking with Large Language Models, Huang and Chen, arXiv 2024. [Paper]
장점 및 단점
- 각 쿼리 문서 쌍의 관련성을 독립적으로 판단하므로 시간 복잡성을 낮추고 배치 inference가 가능
- 다른 방법에 비해 성능면에서 이점이 없음
(2) List-wise Methods
- prompt에 query와 documents들을 전부 넣어준 후, LLM에게 정렬하라고 시키는 방법
- prompt 길이 제한으로 인해 일반적으로 10개~20개 문서만 부분적으로 넣어주고, 슬라이딩 윈도우 기법을 사용함
- 특히 GPT-4 API를 호출할 때 상당한 성능을 제공하지만 비싼 API 비용과 재현 불가능성으로 어려움을 겪음
1. Zero-Shot Listwise Document Reranking with a Large Language Model, Ma et al., arXiv 2023. [Paper]
2. Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent, Sun et al., EMNLP 2023. [Paper] - permutation generation

3. RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze!
4. Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models, Tang et al., arXiv 2023. [Paper]
(3) Pair-wise methods
- GPT-4 API 활용 가능, prompt에 (query, d1, d2) 를 제공해주고, d1, d2 중 더 관련있는 문서를 고르라고 하는 방법
- pairwise 의 결과를 가지고 정말 모든 pair O(N^2) 에 대해서 결과를 구해도 되고, sorting alogrithm을 돌려도 되고, 아니면 sliding widnow라고 두 방법의 중간 정도 되는 방법
1. Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Qin et al., arXiv 2023. [Paper]
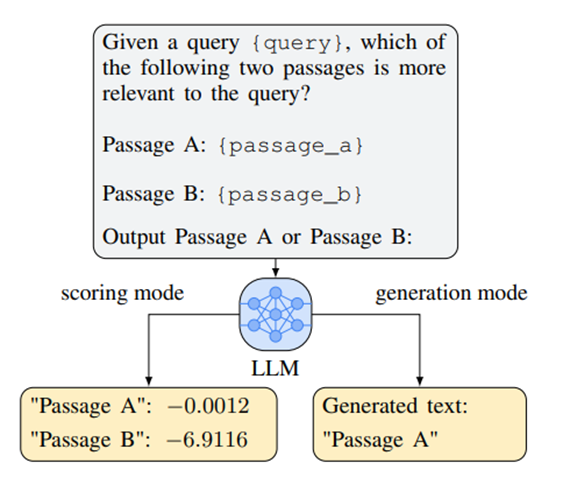
· - query의 순서를 바꿔서 u(q,d1,d2)와 u(q,d2,d1)의 결과를 비교해서 scoring함.

· - all pair comparison 방법 vs Sorting-based 방법(heap 정렬) vs Sliding Window 방법(bubble 정렬과 유사)

- GPT-4 보다 훨씬 더 작은 모형 FLANUL2(20B)를 기반으로 경쟁력 있는 결과를 보여줌. 많은 양의 문서에 대해서 쌍별로 비교해야하므로, 효율성이 낮다는 단점.
2. A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models, Zhuang et al., SIGIR 2024. [Paper]

'AI | DS' 카테고리의 다른 글
| RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL 논문 리뷰 (0) | 2024.05.29 |
|---|---|
| Langchain 정리 (2) | 2024.03.17 |
| Transformer 톺아보기 (1) Positional Encoding (2) | 2023.11.26 |
| Lagrangian Multiplier in ML (0) | 2023.11.26 |
- Total
- Today
- Yesterday
- reranker 속도 개선
- SET문
- ORDER BY LIMIT
- pointwise reranker
- 고전적 추천 알고리즘
- 연관규칙분석
- 하나의 테이블에 대한 조작
- Lagrange Multipler
- 다중 GROUP BY
- NULL AS
- llm reranker
- 추천시스템
- 이코테
- rag 다중문서 활용
- SASRec
- SQL레시피
- treer구조
- NULL인 열 만들어주기
- reranker
- 서브쿼리
- 숨겨진조건
- 여러개 값에 대한 조작
- cold-start
- groupby 다중
- WHERE문 집계함수
- WHERE절서브쿼리
- SELECT문 안 서브쿼리
- 알고리즘
- SQL
- 하이브리드 필터링
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |